Building scalable, reliable, and resilient cloud applications
Posted: January 17, 2024
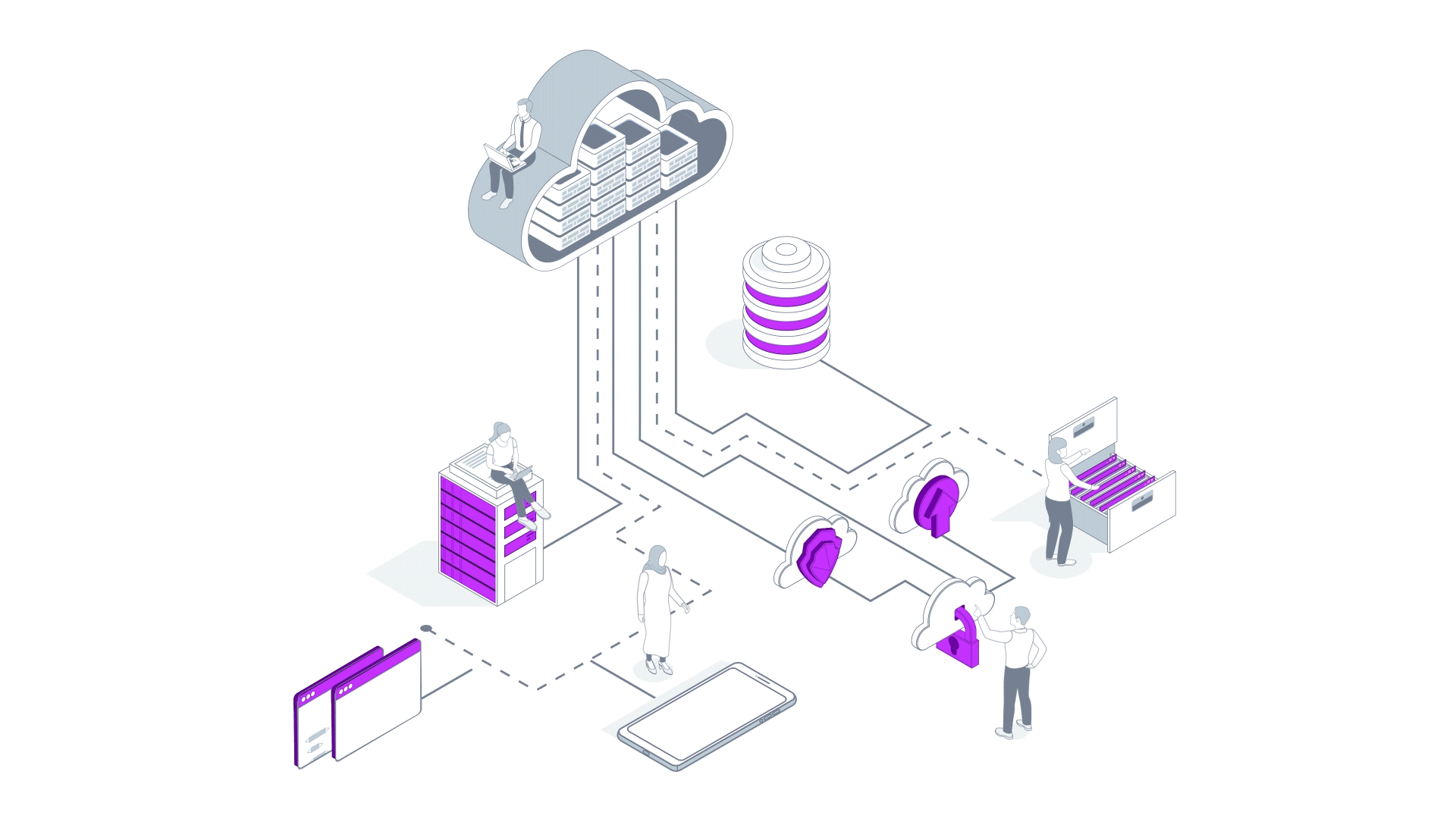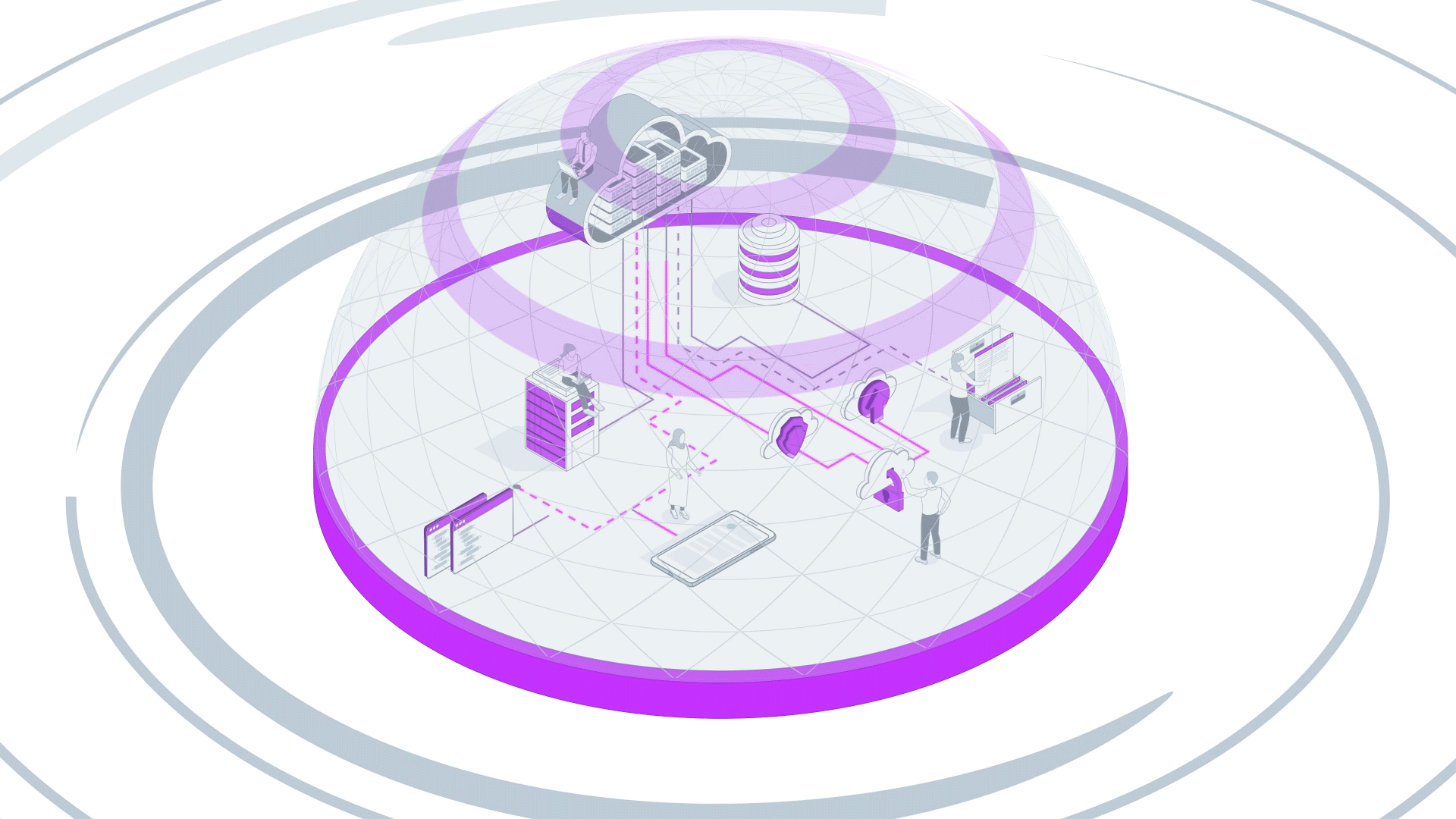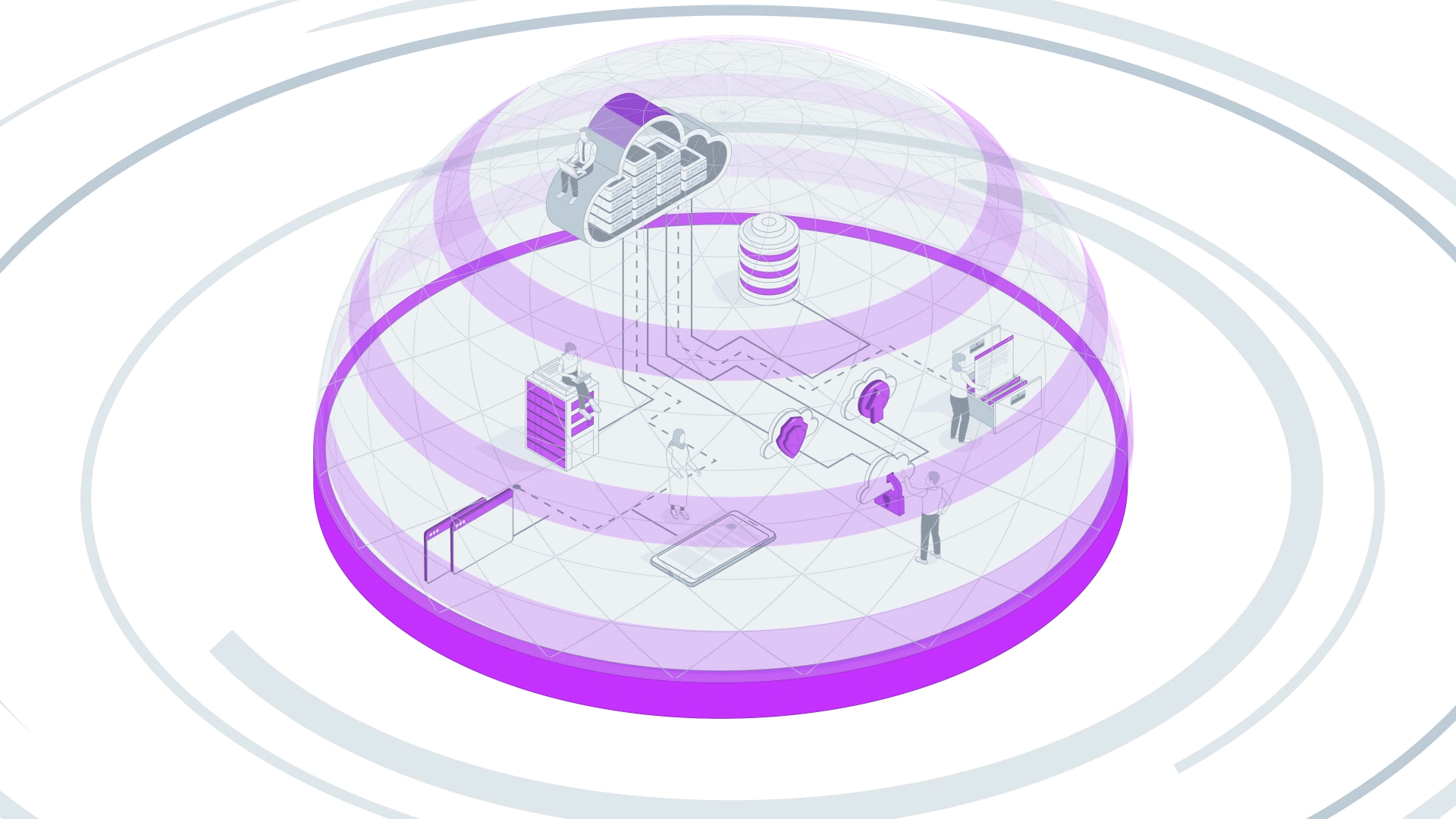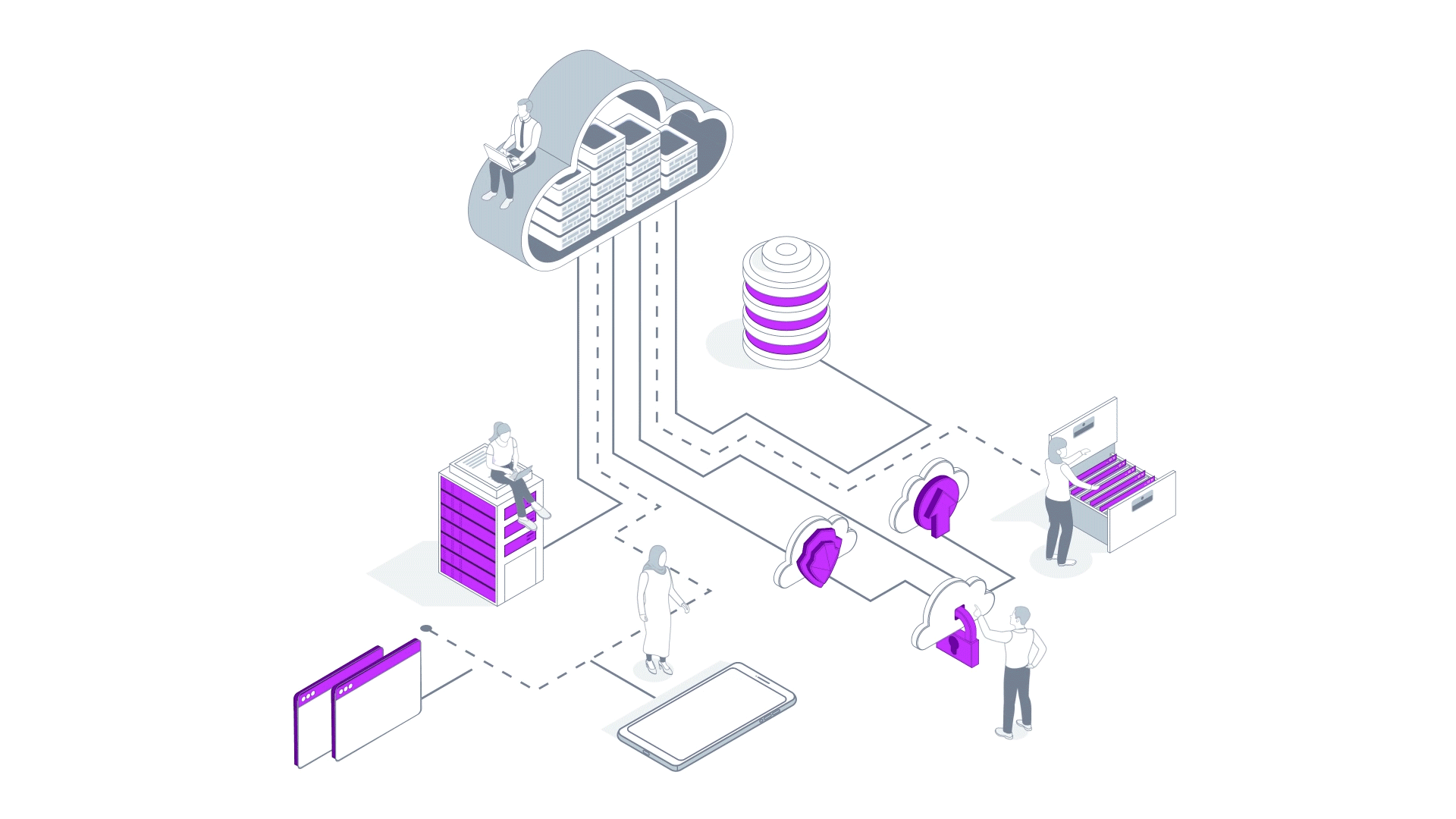
At AVEVA, we design applications for customers in industries such as oil and gas, chemicals, power and utilities, with thousands of users every day. If their application goes down for a few hours, customers are impacted and these interruptions are expensive.
That means our applications need to have superb uptime–but also a strong disaster recovery strategy.
In this blog, we'll go over some of the architectural considerations that we use while building our cloud architecture, including our three guiding principles: High availability, disaster recovery, and operational capabilities of a cloud service.
I'll talk through how we use these principles with an example, using a very simple web app deployed in Azure App services and a small SQL database deployed in Azure Managed SQL.
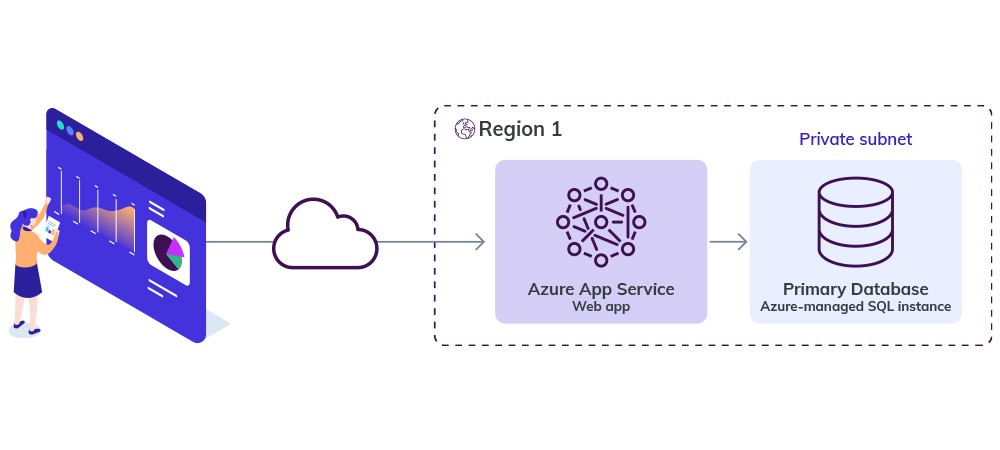 Single region deployment
Single region deployment
This is a web application deployed in a single region (region 1). On the premium tier, it has around 99.95% high availability for Azure app service. An SLA level of 99.95% uptime/availability results in the following periods of acceptable downtime/unavailability during the various reporting periods: 43s every day, 5m 2.4s per week, 21m 44s monthly, and 1h 5m 12s quarterly.
If there is a disaster, our application will be out of service, and you may not be able to restore it to its pre-disaster state. Let’s have a look at how these three concepts can help us solve this.
High availability
The ability of a system or application to remain operational and accessible in the face of failures is referred to as high availability. Eliminating single points of failure, implementing redundancy, and ensuring rapid failover to backup resources in the event of a disruption are all part of achieving high availability. Azure offers a variety of tools and services for developing highly available solutions that can scale and withstand regional or global outages.
Now, for our web app, we could make it highly available with load balancing. To do this, deploy your Azure App service into another region(s) (secondary) and load-balance your requests to those regions based on availability. If your application is up and running in the primary region (region 1), traffic goes to the primary region. If your primary region not available, traffic goes to the secondary regions (region 2).
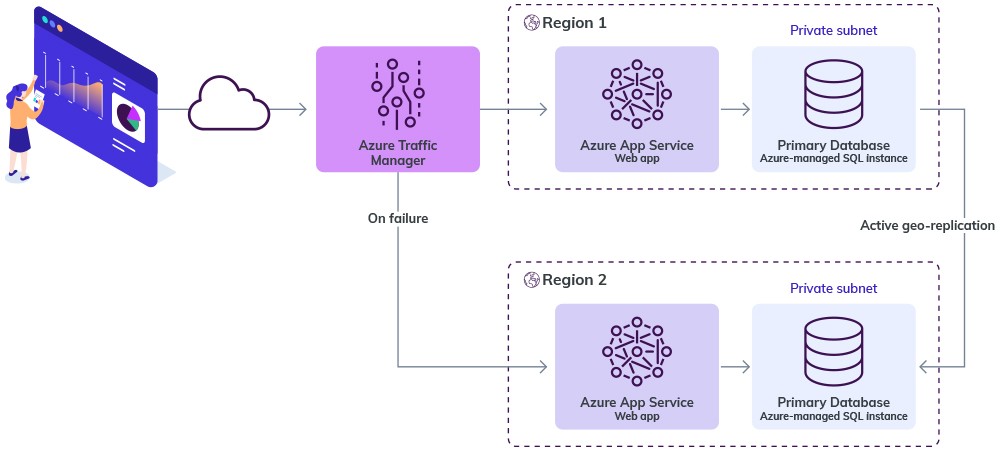 Multi region deployment
Multi region deployment
Here, we used an Azure Traffic Manager to route the traffic between primary and secondary based on health checks.
For SQL Instance, we would deploy another SQL Managed Instance to region 2 and setup active geo-replication for your Azure SQL database. This will replicate our database to databases located in the secondary region. The replication process happens asynchronously in the background and will not affect the performance of our application.
Disaster recovery
Disaster recovery aims to back up your cloud environment's resources, including data and applications. Disaster recovery minimizes downtime for a company that should be operational 99.999% of the time, protects data integrity, and guarantees business continuity.
Azure provides quite a few automated backup disaster recovery options for SQL Server Managed Instances such as Geo-restore, PITR (point-in-time restore), LTR (long-term restore). You can use point-in-time restore to create a database that's a copy of a database at a specific, earlier point in time, which is useful in recovery scenarios. For example, this could be very helpful if you were recovering from an incident caused by error or failure.
Operational capabilities
To ensure that cloud applications are regularly monitored at AVEVA, we:
- Ensure actionable alerts are raised for critical failure modes from all the services deployed
- Connect all alerts to the CDO monitoring system. For example, metric alerts and log alerts are connected to the monitoring system
- Route all alerts to the appropriate channel in Slack
- Determine whether an alert appears in the red or yellow channel based on severity
- Health check all services deployed. Health checks include availability of all internal and external dependencies
- Support the ability to block requests that impact other AVEVA customers
To meet these guidelines for our web app, we can consider integrating Azure Application Insights into our web app to detect, log, and diagnose issues, which would help us make data-driven decisions to improve application performance. It allows us to set up alerts and notifications for critical events and performance thresholds. We can also create alerts for events on Azure App Services and connect them to CDO monitoring framework.
By following these three guiding principles, our solution architects ensure AVEVA cloud applications meet our customers’ needs and are equipped to deal with problems if they occur.
Related blog posts
Stay in the know: Keep up to date on the latest happenings around the industry.